Two teams adopted the same AI coding tool the same week. One got 2x faster. One got slower.

They sat one floor apart. Same tooling rollout, same onboarding session, same week. Both teams were competent — neither was the team you worry about. Six weeks later, one was shipping at close to twice its old throughput. The other was, if anything, slightly slower than before.
The adoption dashboards for both teams looked nearly identical. Usage was high on both floors. If you'd judged the rollout by the metric everyone reaches for first, you'd have concluded it was working equally well everywhere. It wasn't. And the reason had nothing to do with the tool, the training, or the people.
This is the post-mortem.
The setup
I'll call them Team A and Team B, because the point of this isn't which team it was — it's that the difference between them is the difference hiding inside most AI coding rollouts right now, unmeasured.
Both teams were mid-sized, both working on established codebases, both staffed with engineers who'd been shipping for years. When the AI coding tools went in, both teams took to them immediately. Within two weeks, you'd see suggestions being accepted across both floors all day long. By the adoption rate — the number that ends up on the board slide — the rollout was a uniform success.
So when the throughput numbers came back bimodal, the first instinct was to explain it the obvious ways. Maybe Team B had harder work. Maybe Team A had more senior engineers. Maybe it was domain complexity, or tech debt, or morale.
None of those held up. The work was comparable. The seniority mix was comparable. The codebases were both old and both messy in the ordinary ways. Whatever was driving the gap, it wasn't in any of the places you'd look first.
The moment the adoption number stopped meaning anything
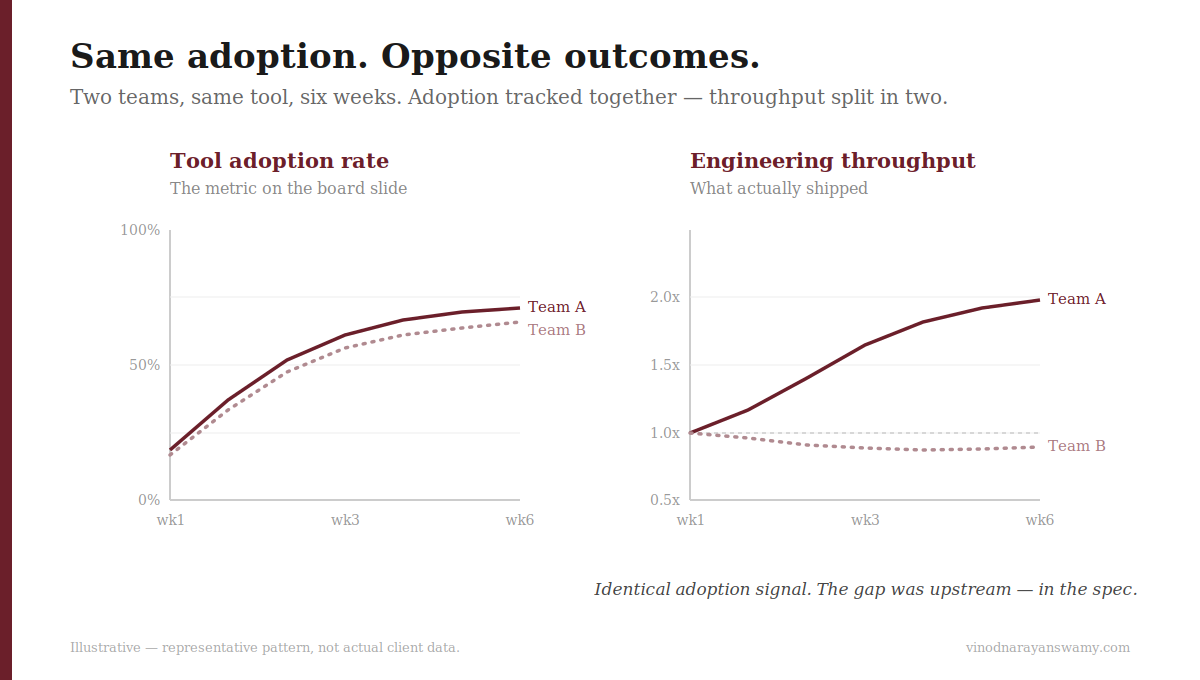
The shape above is representative, not a data export. Both teams' adoption climbed together; only their throughput split.
The thing that broke the puzzle open was watching what happened after a suggestion got accepted.
On Team A, an accepted suggestion mostly stayed. The engineer read it, it was right, it went into the branch, and they moved on. On Team B, an accepted suggestion was the start of the work, not the end of it. The engineer would take the AI's output, realize it had confidently solved the wrong problem — used the wrong entity, missed a constraint nobody had written down, assumed an interface that didn't exist — and then spend the next forty minutes fixing it. The acceptance got logged. The productivity didn't arrive.
That's the trap in measuring adoption: accepting a suggestion and benefiting from it look identical in telemetry. Both teams were "using AI." Only one was getting faster, because only one was feeding the tool something it could actually act on.
Which raised the real question: what did Team A have that Team B didn't?
It was upstream of the keyboard
It wasn't in the IDE. It was in the spec.
When I went back and looked at what each team was actually pulling into their sprints, the difference was stark and consistent. Team A's work items were legible — to a human and, it turned out, to an AI. They named the entities involved. They stated the constraints explicitly. They had acceptance criteria you could check against, and often a concrete example of the expected behavior. An engineer — or a model — could read one and know what "done" meant.
Team B's work items were written the way most work items have always been written: for a human who will fill in the gaps. They assumed you knew which service owned which data. They left the edge cases to "use your judgment." They referenced decisions that lived in someone's head or a three-week-old Slack thread. For years, this worked fine, because the developer did fill in the gaps — that was the job.
AI tools can't fill in gaps they can't see. Hand a model a spec full of unstated assumptions and it does the most dangerous thing possible: it produces something that looks completely plausible and is quietly wrong. The engineer then pays back the entire time savings, and a little extra, debugging a hallucination that a clearer spec would have prevented.
Team A wasn't faster because they were better engineers. They were faster because their specs were AI-legible, and they'd arrived at that almost by accident — a couple of habits in how that team wrote tickets, nothing anyone had mandated.
What the slow team changed
The fix for Team B wasn't more training and it wasn't a different tool. It was moving the quality gate upstream — to the spec, before the work entered a sprint.
The change was unglamorous. Before a work item was allowed into a sprint, someone checked whether it actually contained what an AI tool needs to do the job: the entities named, the constraints written down, acceptance criteria stated, an example where it helped. Items that didn't were sent back to be rewritten before anyone started coding — not after.
It felt like friction at first. It was the opposite. The time spent making a spec legible up front was a fraction of the time the team had been losing to debugging confidently-wrong output on the back end. Within a couple of sprints, Team B's throughput started climbing toward where Team A already was. Same engineers. Same tool. Different inputs.
The part that should worry you
Here's why this is a post-mortem and not just a story.
If you're running an AI coding rollout right now, you almost certainly have a Team A and a Team B. The gap between them is probably large. And you almost certainly can't see it, because the metric you're watching — adoption — is the one metric that's identical across both.
The teams getting the lift and the teams burning it back on rework look the same on your dashboard. Until you start measuring what enters the sprint rather than what happens in the IDE, the bimodal split stays invisible, and you keep reporting an average that describes neither team.
The tool was never the variable. The spec was. The teams that figure this out stop staffing and measuring for a bottleneck that moved months ago. The ones that don't keep wondering why the same rollout produced a rocket on one floor and a rounding error on the next.

